

Jaki problem mają IXP?

Każdy duży Internet Exchange Point to w uproszczeniu jedna wielka domena rozgłoszeniowa — Peering VLAN — nad którą działają setki sesji BGP. AMS-IX używa MPLS/VPLS, DE-CIX przeszedł niedawno na MPLS/EVPN. Technologia się zmienia, ale fundamentalny problem pozostaje: im więcej memberów, tym głośniejszy broadcast i większe ryzyko, że jeden „głośny" uczestnik uderzy w pozostałych.
Andrei Andreev (Melbicom) opisał architekturę, która adresuje ten problem bez uzależnienia od konkretnego vendora. Kluczowa zmiana to zastąpienie portów L2 po stronie IX routowanymi interfejsami unnumbered — pożyczającymi adres IP z Anycast Loopback, identycznego na każdym IX PE.
Efekt? Zamiast jednej płaskiej domeny rozgłoszeniowej powstają mniejsze, izolowane segmenty. Memberzy nie widzą prefiksów infrastruktury IX, a granica między domenami jest wyraźna.
Architektura rozdziela płaszczyzny infrastrukturalne i serwisowe:
- Każdy statyczny /32 kierowany na interfejs membera ma powiązaną sesję BFD (member peering LAN address ↔ anycast IX PE). Przy utracie BFD prefiks infrastrukturalny jest natychmiast wycofywany — i od razu unieważnia zależne od niego prefiksy serwisowe na wszystkich zdalnych PE.
- Prefiksy infrastrukturalne propagują się przez BGP labeled unicast (inet.3), serwisowe przez BGP unicast (inet.0).
- Prefiksy serwisowe istnieją wyłącznie w RIB na PE — nie trafiają do FIB. Filtracja przez community
no-fibzapobiega instalacji na zdalnych boxach.
Ruch serwisowy jest podwójnie tunelowany: tunel IP między ASBR memberów (po adresach Peering LAN) oraz tunel MPLS między IX PE. Po stronie membera wystarczy skonfigurować dynamic tunnels (w tym przykładzie MPLS over UDP) z destination-networks obejmującymi całą przestrzeń adresową Peering LAN.
Jak przyspieszyć analizę PCAP?
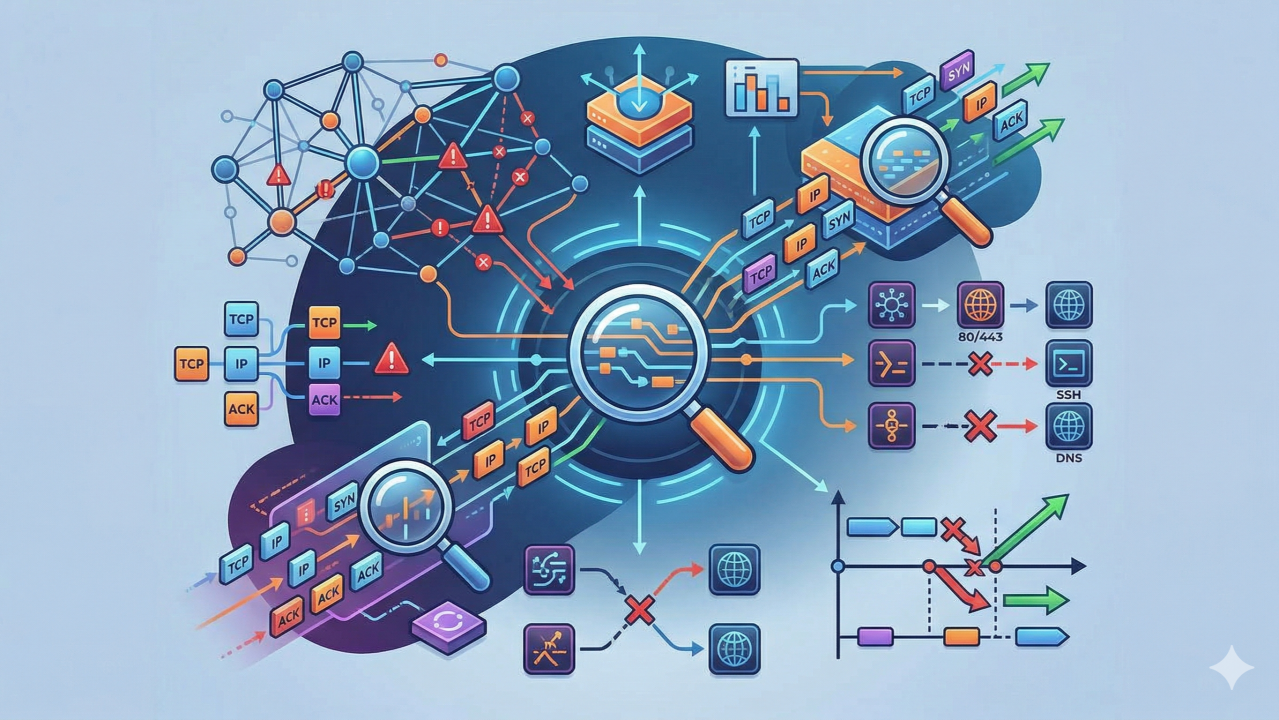
Logi kłamią. Dashboardy kłamią. Pakiety — nie.
Gdy dostajemy zgłoszenie „działa z jednej podsieci, nie działa z drugiej" albo „serwis jest up, ale użytkownicy failują", nie ma sensu zgadywać. Jedyna słuszna odpowiedź to otworzyć capture i spojrzeć na rzeczywisty ruch.
Zanim uruchomisz tcpdump, określ:
- Gdzie przechwycisz ruch — źródło, cel, gateway, czy oba końce?
- Jaki dokładnie flow — src IP, dst IP, port, protokół?
- Jak wygląda sukces — pełny handshake TCP, odpowiedź DNS, negocjacja TLS?
To eliminuje klasyczny błąd: „złapię wszystko i jakoś znajdę".
Techniczne komendy zna każdy. Kluczowe jest szybkie czytanie wzorców:
SYN bez odpowiedzi → filtrowanie, routing lub host down. Możesz retransmitować SYN w kółko bez żadnego RST — to nie odmowa, to cisza.
10:25:00 IP 10.1.10.25 > 10.1.20.99.443: Flags [S]
10:25:01 IP 10.1.10.25 > 10.1.20.99.443: Flags [S] ← retransmit
10:25:03 IP 10.1.10.25 > 10.1.20.99.443: Flags [S] ← retransmit
SYN → natychmiastowy RST → serwis nie nasłuchuje lub lokalny firewall odrzuca. To aktywna odmowa, nie drop.
Pełny handshake, ale aplikacja failuje → schodź wyżej: TLS, certyfikaty, autentykacja.
Jeden kierunek komunikacji → asymetryczny routing lub mismatch polityki stanowej firewalla. Złap oba końce — jeśli request dociera do celu i response wychodzi, ale nie wraca do źródła, masz problem z return path.
Jeden workflow, który robi ogromną różnicę operacyjnie: zamiast kopiować pliki pcap z produkcji, możesz strumieniować pakiety bezpośrednio do lokalnego Wireshark przez SSH.
W Wireshark wybierz interfejs SSH remote capture (sshdump), podaj host, port SSH, credentiale i filtr BPF. Od razu widzisz ruch w czasie rzeczywistym, korzystasz z lokalnych profili i display filters, nie zostawiasz dużych plików na węźle produkcyjnym.
Wymagania na zdalnym hoście: dostęp SSH, zainstalowany tcpdump lub dumpcap, uprawnienia do przechwytywania pakietów. Filtr trzymaj wąski — nie przeciążaj tunelu SSH.
Jeden operacyjny nawyk do wdrożenia dziś
Zbuduj runbook znanych wzorców ruchu dla kluczowych serwisów w swoim środowisku. Jak wygląda zdrowy handshake między app a bazą? Jak wygląda normalny DNS lookup w Kubernetes?
Gdy masz baseline, anomalie widać w ciągu sekund zamiast minut. Różnica między inżynierem, który „patrzy na pakiety" a tym, który „czyta pakiety jak kod" — to właśnie ten kontekst.
Pcap z incydentu zawsze archiwizuj z referencją do ticketu. To nie tylko post-mortem — to materiał dowodowy i baza wiedzy dla całego zespołu.
Pakiety nie kłamią. Zacznij ich słuchać systematycznie.
Lab High-Frequency Trading
Lab w EVE-NG odtwarza infrastrukturę kolokacyjną giełd z BGP, BFD, DPDK i RDMA — technologie stosowane przez firmy takie jak Jump Trading czy Citadel. Pozwala na praktyczną naukę deterministycznego wyboru ścieżek BGP, subsekundowego wykrywania awarii dzięki BFD, filtrowania prefixów, oraz testowanie kernel bypass i szybkiej komunikacji pamięciowej RDMA.
Weryfikacja stanu sieci z AI
blCheck to narzędzie wspomagające walidację sieci w środowiskach multi-vendor z wykorzystaniem AI. Automatycznie sprawdza zgodność aktualnego stanu sieci z założonymi celami (intencjami) zapisanymi w NetBox, a w przypadku wykrycia niezgodności uruchamia agenta Claude, który diagnozuje i dokumentuje błędy. System działa w trybie odczytu, zapewniając bezpieczeństwo, a wyniki są prezentowane na żywym dashboardzie. Dzięki integracji z HashiCorp Vault, NetBox i Jira zarządzanie danymi i rejestrowanie incydentów jest w pełni zautomatyzowane.
Topologia do trenowania AI
Przeczytaj całą historię
Zarejestruj się teraz, aby przeczytać całą historię i uzyskać dostęp do wszystkich postów za tylko dla płacących subskrybentów.
Subskrybuj