

Sponsorem tego wydania jest Sycope, polski producent systemu do monitorowania i analizy ruchu sieciowego w oparciu o analizę przepływów sieciowych (Netflow, IPFIX, sFlow) – zaprasza na webinar na żywo:
👉 „Nieznane urządzenia w sieci? Sprawdź, jak wykryć je bez skanów, agentów i zmian w infrastrukturze!”
📅 31 marca, godz. 11:00
Overclocking IGP
Każdy chce konwergencji poniżej sekundy. Ale agresywne skracanie timerów OSPF czy IS-IS to jedna z najgroźniejszych pułapek w inżynierii sieci — i wciąż zbyt często na nią wpadamy.
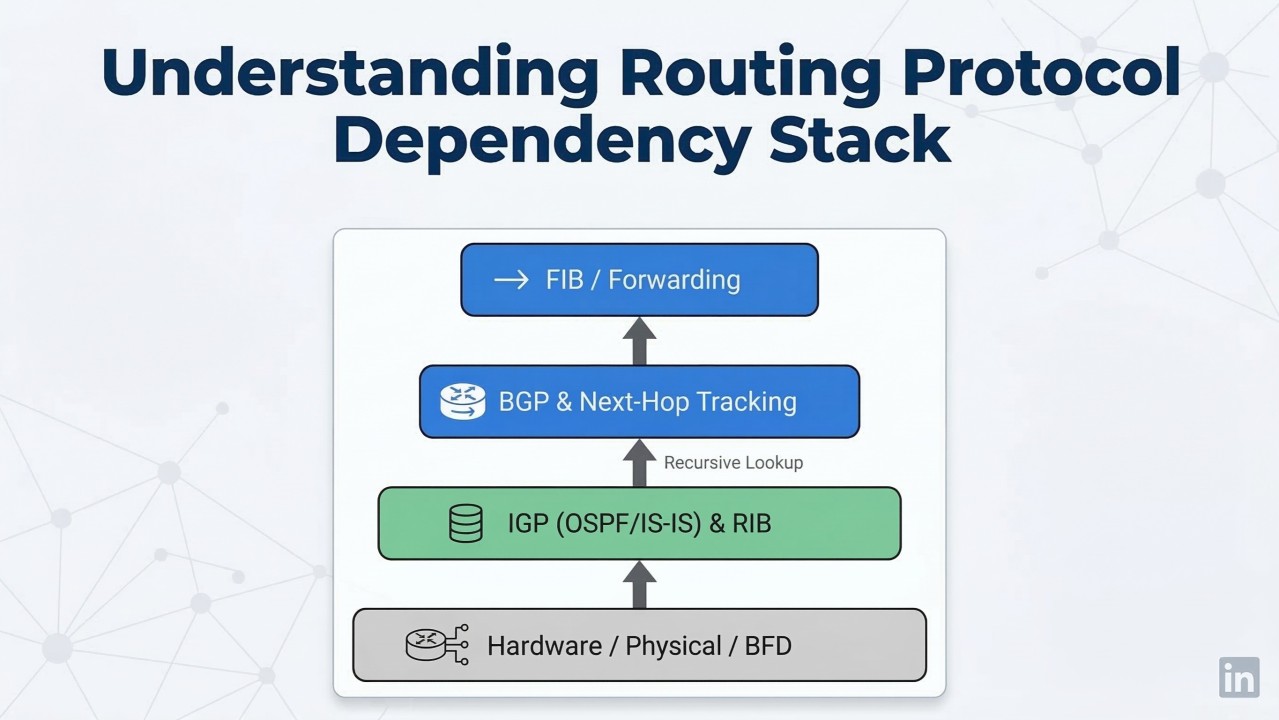
BGP jest tak szybki, jak szybki jest twój IGP
BGP nie działa w próżni. BGP Next-Hop Tracking czeka na przeliczenie ścieżki przez IGP, zanim zaktualizuje własną tablicę. Jeśli OSPF potrzebuje 40 sekund na wykrycie martwego sąsiada, twój ruch BGP przez te 40 sekund trafia w czarną dziurę.
Naturalną reakcją jest "przyspieszenie" protokołu — hello i dead timery bliskie zeru, SPF initial wait zredukowany do minimum. I tu właśnie zaczyna się iluzja.
Fundamentalna zasada, o której łatwo zapomnieć: bezpośrednie awarie interfejsu omijają dead timery całkowicie. Zerwany kabel generuje hardware interrupt, który natychmiast zrywa adjacency. Timery są w takim momencie ignorowane.
Agresywne timery rozwiązują wyłącznie problem silent failures — sytuacji, gdy pośredni switch pada bez sygnału dla routerów na końcach ścieżki. Tymczasem koszt tego "rozwiązania" jest wysoki:
- Control Plane Starvation — awaria line card z dziesiątkami interfejsów powoduje lawinę przerwań. Router próbuje uruchomić SPF osobno dla każdej zmiany stanu. CPU pegged at 100%, IPC głoduje.
- Transient Micro-Loops — Router A aktualizuje FIB w 20ms, Router B w 60ms. Przez 40ms oba odsyłają pakiety do siebie nawzajem, aż TTL nie wygaśnie.
- Złamany High Availability — SSO po awarii supervisora potrzebuje do 10 sekund. Dead timer ustawiony na 3 sekundy spowoduje, że sąsiedzi zerwa adjacency zanim switchover dobiegnie końca. Seamless failover staje się awarią.
Właściwe podejście: hardware zamiast software timerów
Nowoczesna architektura przenosi detekcję awarii z centralnego procesu software'owego na data plane:
BFD (Bidirectional Forwarding Detection) działa bezpośrednio na hardware. Wykrywa awarię w 150ms (3 × 50ms) bez angażowania głównego CPU. To jest właściwe narzędzie do szybkiej detekcji — nie skrócone dead timery.
TI-LFA (Topology-Independent Loop-Free Alternate) prewylicza ścieżkę zapasową. Przy awarii łącza hardware przekierowuje ruch w mniej niż 50ms, zanim IGP zdąży nawet przeliczył topologię.
BGP PIC (Prefix-Independent Convergence) to najważniejszy element układanki dla sieci z dużą tablicą BGP. PIC pre-instaluje zapasowe next-hopy bezpośrednio w hardware FIB. Przy awarii łącza tranzytowego (PIC Core) lub zewnętrznego peera (PIC Edge) hardware zmienia jeden wskaźnik — niezależnie od rozmiaru tablicy routingu.
Protokół A2A
Budowanie wieloagentowych systemów automatyzacji sieci wygląda świetnie na slajdach. W praktyce kończy się na tygodniach pisania glue code'u między agentami, które mówią różnymi językami. Agent2Agent (A2A) od Google rozwiązuje dokładnie ten problem.
A2A to otwarty protokół standaryzujący komunikację między agentami AI — niezależnie od frameworka, vendora czy środowiska. Działa na HTTP/S z JSON-RPC, co oznacza, że pasuje do istniejącej infrastruktury enterprise bez przebudowy czegokolwiek.
Trzy kluczowe elementy:
- Agent Card — plik JSON publikowany przez każdego agenta, opisujący jego możliwości, endpoint i wymagania auth. Odpowiednik DNS dla agentów — discovery bez hardcodowania zależności.
- Tasks — jednostki pracy z pełnym lifecycle (submitted → working → completed/failed). Persystują przez wiele interakcji i zachowują stan nawet gdy zależności są niedostępne.
- Messages — krótkie, bezstanowe interakcje dla prostych zapytań.
Ważna różnica w stosunku do MCP: A2A to komunikacja pozioma (agent ↔ agent), MCP to komunikacja pionowa (agent → narzędzia/toolsy). Oba są potrzebne w kompletnym systemie.
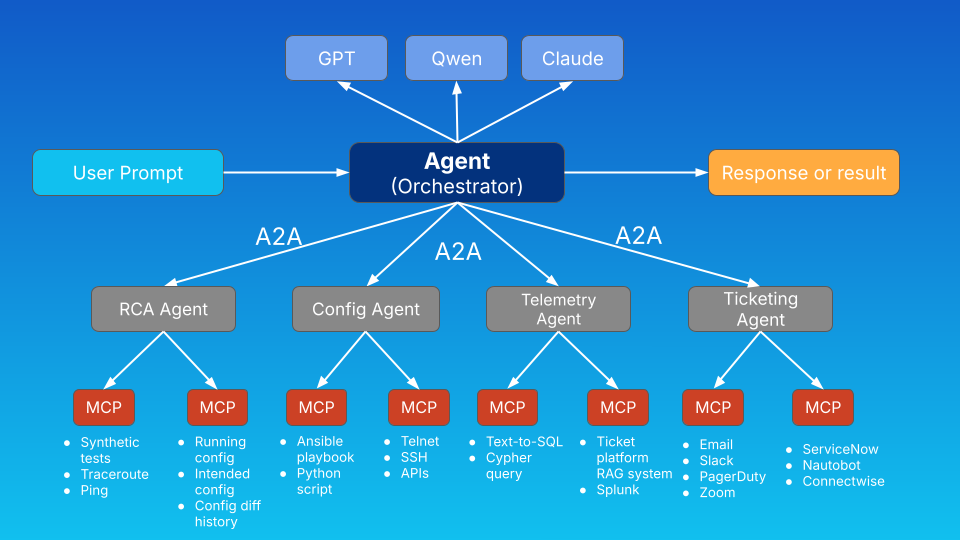
Typowy workflow RCA w złożonej sieci wymaga danych telemetrycznych, przeszukania dokumentacji, analizy topologii, generowania configu i aktualizacji ticketów. Bez A2A każda integracja między komponentami to osobny projekt.
Z A2A możesz zbudować specjalizowane agenty (telemetria, topologia, konfiguracja, ticketing) które współpracują przez wspólny protokół. Każdy agent ma własne narzędzia przez MCP, własne uprawnienia, własne logi. Możesz upgradeować jeden agent bez dotykania pozostałych.
Konkretny przykład: alert o wysokim wykorzystaniu interfejsu trafia do agenta RCA. Ten wysyła zadanie do Telemetry Agent po dane z 6 godzin, do Topology Agent po kontekst LLDP/CDP, do Configuration Agent po propozycję remediacji. Na końcu Ticketing Agent aktualizuje ServiceNow i czeka na ludzką akceptację przed pushowaniem zmian. Cały workflow ma pełny audit trail — kto poprosił o co, co zwróciło jakie dane, co zostało zaaplikowane.
Jeśli budujesz lub planujesz automatyzację opartą na AI, warto zacząć od jednego agenta z kilkoma MCP serverami — nie od razu od pełnej architektury wieloagentowej. Natura A2A sprawia jednak, że skalowanie jest przewidywalne: dodajesz nowego agenta z jego Agent Card, a reszta systemu może go automatycznie odkryć i zacząć delegować zadania.
Szwajcarski scyzoryk sieciowca

Aplikacja oferuje zaawansowane kalkulatory i symulatory do pracy z IPv4 i IPv6, w tym kalkulatory podsieci, planowanie VLSM, analizę adresów IPv6 oraz symulacje protokołów takich jak STP, OSPF czy BGP. Dzięki przejrzystym wizualizacjom, dokładnym wyjaśnieniom i zestawom pytań do egzaminów CCNA/CCNP, SubnetLab Pro jest idealnym wsparciem dla studentów i inżynierów sieciowych na różnych poziomach zaawansowania.
Każdego dnia w Twojej sieci pojawiają się urządzenia, nad którymi nikt nie ma pełnej kontroli i często pozostają niewidoczne – aż do momentu incydentu lub audytu.
Sycope – polski producent systemu do monitorowania i analizy ruchu sieciowego w oparciu o analizę przepływów sieciowych (Netflow, IPFIX, sFlow) – zaprasza na webinar na żywo:
👉 „Nieznane urządzenia w sieci? Sprawdź, jak wykryć je bez skanów, agentów i zmian w infrastrukturze!”
📅 31 marca, godz. 11:00
Podczas webinaru dowiesz się:
☑️ dlaczego nieznane urządzenia to realne ryzyko;
☑️ czego nie widzą klasyczne narzędzia;
☑️ jak wykrywać urządzenia pasywnie (bez skanów i agentów);
☑️ jak przejść od wykrycia do realnych działań.
Dashboard do monitorowania MikroTik-a
MikroDash to zaawansowany dashboard do monitorowania MikroTik RouterOS w czasie rzeczywistym. Łączy się bezpośrednio z API routera przez stałe połączenie TCP i przesyła dane na żywo do przeglądarki bez konieczności odświeżania strony. Obsługuje wiele funkcji: wykresy ruchu, status systemu, mapę połączeń, klientów bezprzewodowych, interfejsy, DHCP, VPN/WireGuard, zaporę i wiele innych.
Lab IPv6
Przeczytaj całą historię
Zarejestruj się teraz, aby przeczytać całą historię i uzyskać dostęp do wszystkich postów za tylko dla płacących subskrybentów.
Subskrybuj