

Nowoczesna blokada internetu
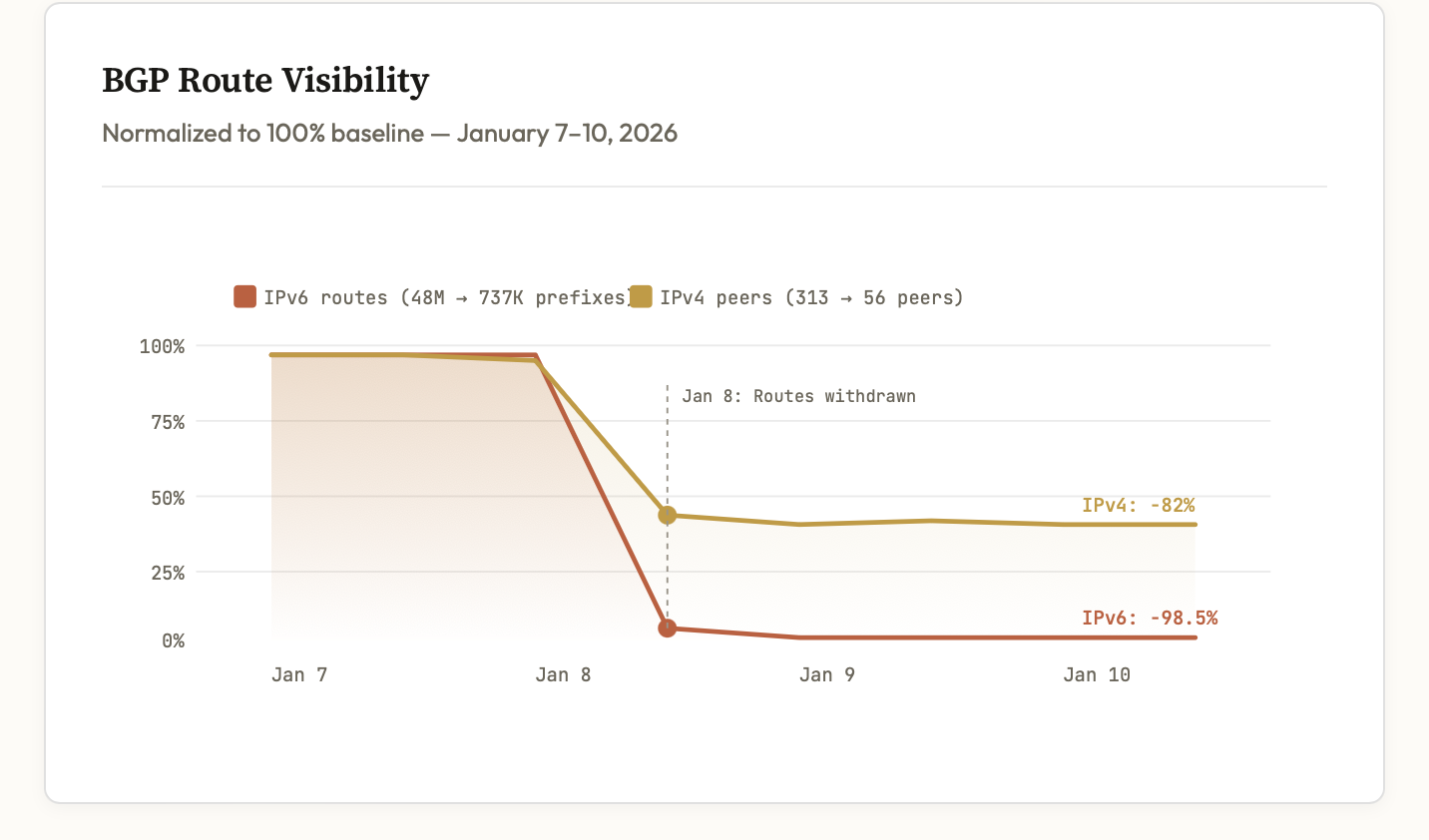
Od 8 stycznia 2026 Iran praktycznie zniknął z internetu. Ale to nie jest klasyczny shutdown, który widzieliśmy wcześniej – to coś znacznie bardziej wyrafinowanego.
Tradycyjne blokady działały prosto: kraj wycofywał swoje prefiksy BGP i znikał z tablic routingu. Łatwo wykryć, łatwo udokumentować.
Iran w 2026 pokazał inną drogę:
- IPv6: kompletnie wycofane z BGP (-98.5% tras)
- IPv4: trasy pozostają UP w BGP, ale ruch blokowany na poziomie sieciowym
- Efekt: monitoring BGP pokazuje "wszystko działa", analiza ruchu ujawnia blokadę
To "stealth outage" – infrastruktura wygląda funkcjonalnie w systemach monitoringu, podczas gdy faktyczna łączność spada do zera. Potrzebujesz korelacji BGP + analiza ruchu, żeby złapać pełen obraz.
Dlaczego Iran może to zrobić, a większość krajów nie? Wszystkie połączenia międzynarodowe przechodzą przez dwa gateway-e: TIC i IPM, oba pod kontrolą państwa.
Nie ma alternatywnych ścieżek. Nie ma redundancji. Każdy irański ISP, operator mobilny, provider biznesowy – wszyscy muszą przejść przez te dwa punkty. Gdy TIC i IPM koordynują blokadę, 87 milionów ludzi jest offline.
To drastyczna lekcja architektury: centralizacja punktów wymiany ruchu międzynarodowego tworzy idealny Kill Switch. Żadna ilość wewnętrznej redundancji nie pomoże, gdy wszystkie ścieżki na zewnątrz zbiegają się w dwóch kontrolowanych miejscach.
Blokada nie jest hermetyczna – to system whitelistingu. Część infrastruktury pozostaje online:
- Instytucje państwowe
- Wybrane banki
- Systemy propagandowe
Monitoring pokazuje ruch z "uprzywilejowanych ASN", podczas gdy cywilna populacja jest odcięta. Asymetryczna blokada: państwo jest online, obywatele nie.
Niektórzy użytkownicy z odpowiednimi narzędziami przebijają się przez "przecieki" – niekompletne blokady w sieciach biznesowych, DNS tunneling (dnstt), VPN-y wykorzystujące luki. Działa, ale jest wolno, niestabilnie i wymaga wiedzy technicznej.
Co to oznacza dla nas?
Trzy praktyczne wnioski:
1. Monitoruj wielowarstwowo: Samo BGP nie wystarczy. Stealth outages wymagają korelacji routingu + traffic telemetry + application-layer probes.
2. Audytuj zależności geograficzne: Czy Twoja infrastruktura przechodzi przez kraje z centralnymi gateway-ami? Jakie są alternatywne ścieżki jeśli region X znika z internetu?
3. Obserwuj datasety: NetBlocks, IODA (Georgia Tech), RIPE RIS, Cloudflare Radar – to źródła real-time data o tego typu eventach. Iran nie będzie ostatnim przypadkiem.
Co było pierwsze: CNAME czy rekord A?

8 stycznia 2026 rutynowa aktualizacja resolvera 1.1.1.1 Cloudflare wywołała falę błędów rozwiązywania DNS dla użytkowników na całym świecie. Przyczyna? Zmiana kolejności rekordów w odpowiedziach DNS. Brzmi absurdalnie? Zagłębmy się w 40-letnie zawiłości protokołu.
Cloudflare zmodyfikował kod obsługujący częściowo wygasłe łańcuchy CNAME, aby zredukować alokacje pamięci. Poprzednio kod tworzył nową listę, wstawiał istniejący łańcuch CNAME, a następnie dodawał nowe rekordy:
answer_rrs.extend_from_slice(&self.records); // CNAMEs pierwsze
answer_rrs.extend_from_slice(&entry.answer); // Potem A/AAAA
Nowa logika
entry.answer.extend(self.records); // CNAMEs ostatnie
Po optymalizacji CNAME-y trafiały na koniec odpowiedzi. Efekt? Funkcja getaddrinfo w glibc (podstawa resolwingu DNS w Linuksie) przestała działać. Implementacja parsuje rekordy sekwencyjnie - gdy napotka CNAME, aktualizuje "oczekiwaną nazwę". Jeśli rekord A pojawia się PRZED CNAME, zostaje zignorowany jako niezgodny z oczekiwaniem.
Bardziej drastyczny skutek: przełączniki Cisco trzech modeli wpadły w pętle rebootów przy użyciu 1.1.1.1.
RFC 1034 z 1987 roku mówi, że odpowiedź może być "possibly preface by one or more CNAME RRs". Problem? To nie jest normatywne stwierdzenie z użyciem słów MUST/SHOULD (które RFC 2119 zdefiniował dopiero 10 lat później). RFC jasno określa, że kolejność w RRset nie ma znaczenia, ale nie precyzuje relacji między różnymi RRsetami w sekcji odpowiedzi.
Późniejsze specyfikacje (np. RFC 4035 dla DNSSEC) są bardziej jednoznaczne: "MUST also place its RRSIG RRs" z "higher priority for inclusion". Ale dla niezabezpieczonych stref - dwuznaczność pozostaje.
Większość nowoczesnych resolverów (np. systemd-resolved) parsuje najpierw wszystkie rekordy do uporządkowanego zestawu, dzięki czemu kolejność nie ma znaczenia. Ale legacy systems polegają na założeniach sprzed dekad.
Monitorowanie opóźnień

latency-monitor to lekki i precyzyjny program do monitorowania opóźnień TCP i UDP, mierzący czas jednokierunkowy i rundy do wskazanych hostów. Dzięki elastycznemu interfejsowi możesz publikować metryki do różnych backendów, jak Datadog, ClickHouse czy ZeroMQ. Konfiguracja odbywa się przez plik latency.toml lub argumenty CLI, pozwalając dostosować cele, porty, częstotliwość pomiarów czy typ protokołu.
Kalkulator podsieci
Interaktywny kalkulator podsieci dla IPv4 oraz IPv6 prezentuje wszystkie najważniejsze informacje w przystępnej formie. Znajdziesz tu dane o wielkości podsieci, liczbie dostępnych adresów dla hostów, masce wildcard i innych istotnych parametrach.
DNS Tunneling
Przeczytaj całą historię
Zarejestruj się teraz, aby przeczytać całą historię i uzyskać dostęp do wszystkich postów za tylko dla płacących subskrybentów.
Subskrybuj