

Globalne awarie w Q4

Ostatni kwartał 2025 zapisze się jako okres najbardziej spektakularnych awarii w historii usług chmurowych. AWS, Azure i Cloudflare - wszyscy po kolei. A winowajca? Nie cyberataki, lecz bugi w automatyzacji.
AWS: gdy DNS zawiodło bazę danych
21 października DynamoDB padło na kilka godzin. Przyczyna? Wadliwe oprogramowanie zarządzające DNS dla tej usługi. Systemy AWS i aplikacje klientów nie mogły tłumaczyć nazw hostów na adresy IP - połączenia niemożliwe. Według post-mortem, problem był w zarządzaniu rekordami DNS, co uniemożliwiło dostęp do jednej z najpopularniejszych baz NoSQL w chmurze.
Azure: konflikt wersji w globalnej skali
Dni później Microsoft doświadczył własnej katastrofy. Klient wprowadził poprawną zmianę konfiguracyjną w Azure Front Door, ale ta została przetworzona przez dwie różne wersje control-plane, generując niezgodne metadane. Gdy te dane rozprzestrzeniły się globalnie, wywołały ukrytego buga w warstwie data plane - masowe awarie i problemy z wewnętrznym DNS na edge sites.
Cloudflare: gdy Bot Management urósł za bardzo
18 listopada drobna zmiana uprawnień w bazie danych Cloudflare wygenerowała plik konfiguracyjny dla Bot Management dwukrotnie większy niż normalnie. Oversized file przekroczył limity w kluczowym module proxy i wywołał globalną awarię. Na początku objawy przypominały masowy atak DDoS, co dodatkowo skomplikowało diagnozę.
Co naprawdę się nie zepsuło
W każdym przypadku podstawy internetu działały bez zarzutu: żadne kable światłowodowe nie zostały przecięte, globalnie DNS i BGP funkcjonowały prawidłowo. Internet, zaprojektowany by przetrwać wojnę nuklearną, nigdy nie leżał. Problem tkwił wyłącznie w wewnętrznych systemach poszczególnych dostawców.
Kluczowy wniosek? Od lat to nie cyberataki, a bugi w automatyzacji są główną przyczyną wieloskalowych awarii. Operowanie w tej skali wymaga automatyzacji, ale ciągły push na nowe funkcje zwiększa złożoność i ryzyko katastrofalnych błędów.
Dla zespołów, które nie mogą sobie pozwolić na kilkugodzinne przestoje raz-dwa w roku, rozwiązanie jest jedno: dywersyfikacja hostingu. Pozostali będą musieli po prostu przetrwać - ale dzięki konsolidacji rynku, przynajmniej w dobrym towarzystwie.
Szybsza konwergencja BGP
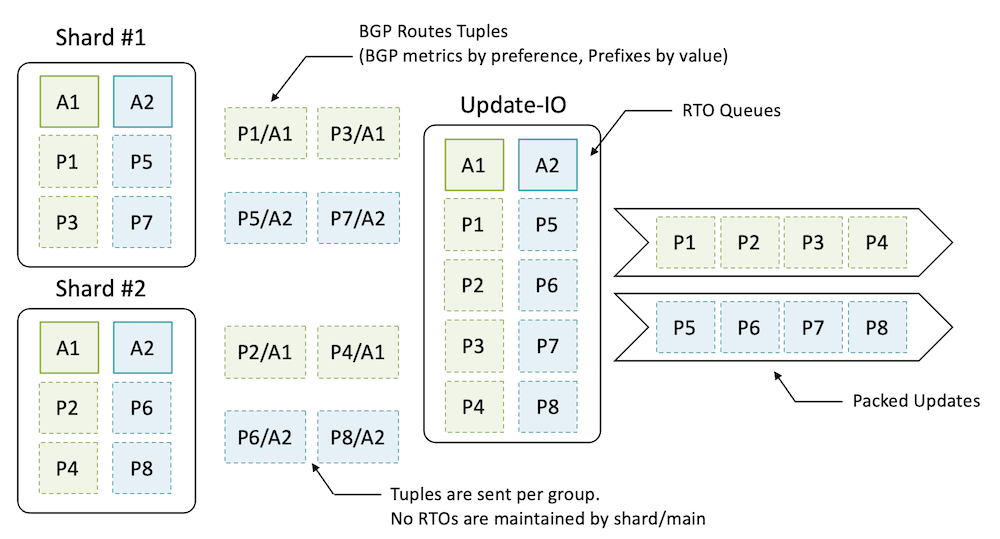
Juniper wprowadził do JUNOS architekturę RIB Sharding – rozwiązanie, które dzieli tablicę routingu BGP na niezależne fragmenty obsługiwane równolegle przez dedykowane wątki. W testach laboratoryjnych osiągnięto do 9-krotne przyspieszenie konwergencji. Jak to działa i kiedy warto to wdrożyć?
Tradycyjny RPD (Routing Protocols Daemon) działał w jednym wątku, co przy milionach prefiksów BGP stawało się wąskim gardłem. Pipeline BGP – od otrzymania UPDATE przez best path selection po generowanie wiadomości do peerów – wykonywał się sekwencyjnie. Wprowadzenie wątków I/O (BGP-IO) pomogło w komunikacji, ale główny processing wciąż blokował się na jednym rdzeniu.
Juniper zastosował sharding RIB – każdy shard to niezależny wycinek tablicy routingu obsługiwany przez dedykowany wątek. Kluczowe założenia:
- Hash z prefiksu IP określa, który shard obsługuje dany prefix
- Zero synchronizacji między shardami – każdy ma własny mini-ekosystem RPD
- Update threads agregują wyniki z shardów, pakując prefiksy z tymi samymi atrybutami w jednym UPDATE (unikając rozdrobnienia wiadomości)
- Eventual consistency – protokoły routingu z natury tolerują chwilowe rozbieżności
W testach z cRPD (24 rdzenie, 8M prefiksów inbound, 800M outbound do 1000 peerów) konwergencja z 12 shardami + 12 update threads była 9x szybsza niż bez shardingu.
Sharding błyszczy w scenariuszach z:
- Dużą skalą (miliony prefiksów)
- Wysokim RIB-FIB ratio (wiele peerów uczy tych samych prefiksów) – typowo 4:1 lub więcej
- Control plane only – Route Reflectors są idealnym use case'em (brak FIB download = minimalna praca w main thread)
Przykłady z produkcji:
- PTX10003 peering router (11M routes, 200 eBGP peers): 4x przyspieszenie z 12 shardami
- MX480 DC edge (7M IPv4, 900 peers): 2.5x przyspieszenie z 2 shardami (4 rdzenie CPU)
Deployment A (tier 1 SP, MX204 RR): 150 peerów, 10M IPv4 (12:1 ratio), 5 shardów – stable production.
Co jeszcze musisz wiedzieć?
- Sharding nie wymaga przepisywania kodu – istniejący RPD działa w każdym shardzie bez zmian
- Liczba shardów = liczba rdzeni daje najlepsze wyniki (więcej = scheduling overhead)
- Optimal Route Reflection (ORR) zyskuje najwięcej – compute-intensive per-client best path w każdym shardzie równolegle
- Koszt: dodatkowa komunikacja między wątkami – opłaca się od skali ~1M+ prefiksów
Geolokalizacja po opóźnieniach
Narzędzie do lokalizacji IP na podstawie opóźnień (latency) wykorzystuje Globalping do określenia fizycznej lokalizacji adresu IP. Instalacja i użycie jest proste — wystarczy sklonować repozytorium, zainstalować zależności i uruchomić komendę geolocate.
Porównanie chmur w czasie rzeczywistym
Serwis oferuje kompleksową analizę wydajności i dostępności usług chmurowych na podstawie milionów testów globalnych. Możesz porównać popularnych dostawców, takich jak Amazon Web Services, Google Cloud, Exoscale czy Vultr, uwzględniając różne lokalizacje geograficzne. Platforma pokazuje opóźnienia (latency) i dostępność (uptime) w czasie rzeczywistym, co pozwala wybrać najlepszy region i usługę chmurową dopasowaną do twoich potrzeb.
Jak wybrać narzędzia do automatyzacji infrastruktury
Przeczytaj całą historię
Zarejestruj się teraz, aby przeczytać całą historię i uzyskać dostęp do wszystkich postów za tylko dla płacących subskrybentów.
Subskrybuj