

Darmowe szkolenia z CML

Cisco właśnie zdjęło paywall z kompletnych ścieżek szkoleniowych CML na platformie Cisco U. Materiały, które do tej pory wymagały płatnej subskrypcji (Essentials/All Access), są teraz dostępne dla każdego.
Konkretnie mówimy o:
Każda ścieżka to gotowy program szkoleniowy z labami i praktycznymi scenariuszami.
Jeśli CML jest w twoim stack'u lub planujesz jego wdrożenie - poświęć godzinę na przejrzenie tych ścieżek. Nawet jeśli znasz platformę, sekcja automation może pokazać podejścia, których nie brałeś pod uwagę.
Materiały znajdziesz bezpośrednio na Cisco U - wystarczy darmowe konto.
Logging vs Observability
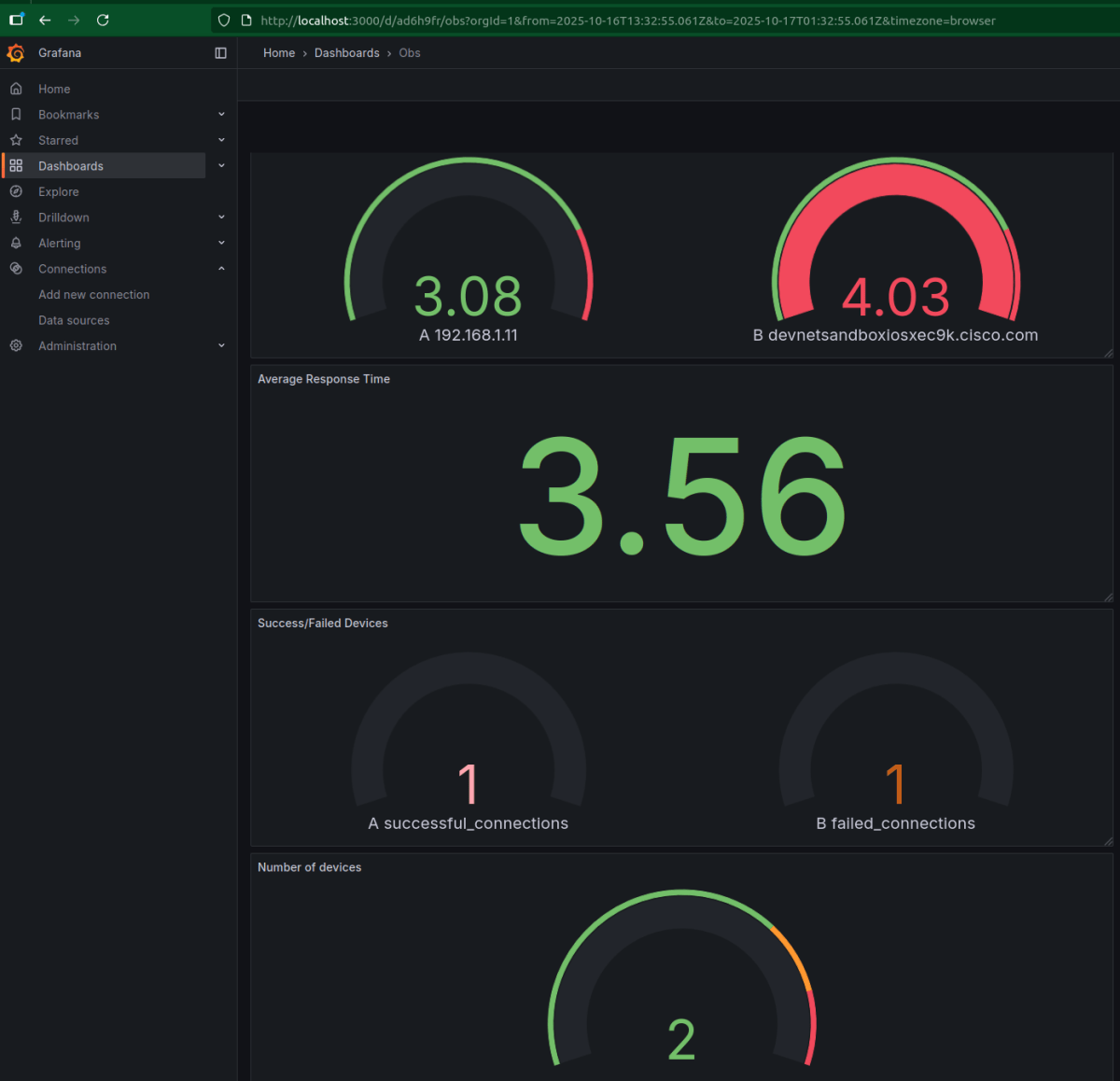
Piszesz skrypty Pythona do automatyzacji sieci? Świetnie działają na kilku urządzeniach, ale czy wiesz, co się dzieje, gdy coś pójdzie nie tak? Różnica między loggingiem a observability może zadecydować, czy problem rozwiążesz w 5 minut, czy będziesz debugować pół dnia.
Typowy skrypt Netmiko łączy się z urządzeniem, wykonuje komendy i... to wszystko. Dodanie logging z poziomami DEBUG/INFO/ERROR daje podstawową widoczność - wiesz co się wydarzyło i kiedy. Ale to jedynie szczegóły pojedynczego zdarzenia.
Problem zaczyna się, gdy automatyzujesz 50 urządzeń. Logging odpowie "połączenie z 192.168.1.11 nie powiodło się", ale nie powie:
- Ile urządzeń faktycznie zawiodło?
- Jaki jest średni czas odpowiedzi?
- Które urządzenie działa najwolniej?
To pytania, na które samo logowanie zdarzeń nie odpowie.
Observability to krok dalej - zamiast tylko zapisywać zdarzenia, zbierasz strukturalne metryki całej aplikacji. W praktyce: zapisujesz nie tylko logi tekstowe, ale JSON z danymi:
{
"total_devices": 3,
"successful": 2,
"failed": 1,
"avg_response_time": 1.88,
"device_metrics": {...}
}
Taki output można wysłać do Grafany przez JSON API (prosty python -m http.server wystarczy). Nagle widzisz trendy, porównujesz wydajność między urządzeniami, identyfikujesz wąskie gardła. To różnica między "coś nie działa" a "wiem dokładnie co i dlaczego".
Dla jednego skryptu na 3 urządzenia - logging wystarczy. Ale jeśli budujesz:
- Multi-device workflows z kolejnymi zależnościami
- Aplikacje z frontendem/backendem/bazą danych
- Cokolwiek, co działa w produkcji dłużej niż tydzień
...to observability przestaje być luksusem, a staje się koniecznością. Bo w produkcji nie pytasz "czy działa", tylko "jak szybko działa i gdzie się zacina".
Weź swój największy skrypt automatyzacji. Dodaj do niego:
- Pomiar czasu wykonania (
time.time()) - Liczniki sukces/porażka
- Zapis do JSON zamiast tylko print/log
Następnym razem, gdy coś zwolni o 30%, będziesz wiedział o tym, zanim użytkownicy zaczną zgłaszać problemy.
Open Source GFW

OpenGFW to otwarte oprogramowanie dla Linuksa umożliwiające zbudowanie własnej wersji „Great Firewall of China”. Projekt oferuje inspekcję i filtrowanie ruchu na wielu warstwach (HTTP, TLS, QUIC, DNS, SSH, SOCKS4/5, WireGuard, OpenVPN i inne), detekcję „w pełni zaszyfrowanego ruchu” (np. Shadowsocks, VMess), wykrywanie Trojan/proxy oraz wsparcie dla analiz protokołów i wielowątkowego przetwarzania przepływów.
Diagramy Terroform

Terramaid tworzy diagramy Mermaid na podstawie konfiguracji i planów Terraform. Dostępne są przykładowe integracje CI/CD (GitHub Actions, GitLab)
Tip: można testować Terramaid w przeglądarce przez GitHub Codespaces.
Od Ansible do ChatGPT
Przeczytaj całą historię
Zarejestruj się teraz, aby przeczytać całą historię i uzyskać dostęp do wszystkich postów za tylko dla płacących subskrybentów.
Subskrybuj