

Kiedy bufory sieciowe zawodzą
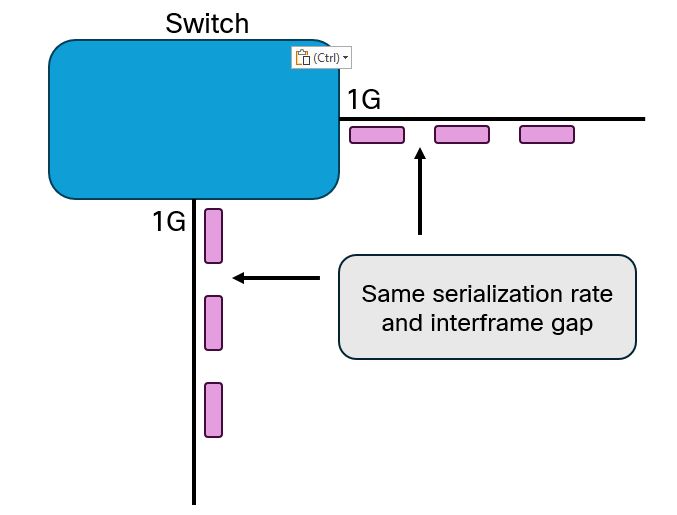
Aby zrozumieć przyczyny output drops, musimy najpierw przeanalizować dwa kluczowe pojęcia, które determinują zachowanie interfejsów sieciowych.
Szybkość szeregowania (Serialization Rate)
Szybkość szeregowania określa, jak szybko ramki są odbierane i transmitowane przez interfejs. Proces ten zachodzi z prędkością interfejsu - 1 Gbit/s, 10 Gbit/s, czy 100 Gbit/s.
Rozważmy praktyczny przykład: ramka o wielkości 512 bajtów na łączu 1 Gbit/s wymaga 4096 nanosekund do pełnego szeregowania. Na łączu 10 Gbit/s ten sam proces trwa jedynie 409,6 nanosekund - różnica dziesięciokrotna.
Przerwa międzyramkowa (Interframe Gap)
IFG to obowiązkowy okres bezczynności między kolejnymi ramkami, wynoszący standardowo 12 bajtów (96 bitów). Na łączu 1 Gbit/s oznacza to 96 nanosekund przerwy, podczas gdy na 10 Gbit/s jedynie 9,6 nanosekund.
Scenariusze prowadzące do output drops
Przejście z wyższej na niższą prędkość
Problemy pojawiają się, gdy interfejs 10 Gbit/s przekazuje ruch na interfejs 1 Gbit/s. Interfejs odbiorczy może przyjmować dane dziesięć razy szybciej niż interfejs nadawczy jest w stanie je wysyłać. Dodatkowo krótsze przerwy międzyramkowe potęgują problem.
Agregacja wielu interfejsów
Gdy kilka interfejsów 1 Gbit/s przekazuje ruch na jeden interfejs wyjściowy, może dojść do sytuacji, gdzie ramki docierają niemal jednocześnie. Interfejs wyjściowy musi zachować wymagane IFG między kolejnymi ramkami, co wymusza buforowanie.
Rozważmy eksperyment myślowy: łącze 10 Gbit/s z przeciętnym wykorzystaniem 5 Gbit/s zostaje zastąpione łączem 40 Gbit/s. Jaki wpływ ma to na bufory?
Paradoksalnie, szybszy interfejs może zwiększyć presję na bufory. Krótsze IFG i szybsze szeregowanie oznaczają, że ramki docierają do interfejsów wyjściowych w bardziej zagęszczonych pakietach, wymagając większej pojemności buforowania.
Praktyczne implikacje dla architektury sieci
Każde przejście z wyższej na niższą prędkość stanowi potencjalny punkt przeciążenia. Szczególną uwagę należy zwrócić na:
- Połączenia między rdzeniem a dystrybucją
- Łącza WAN o ograniczonej przepustowości
- Interfejsy agregujące ruch z wielu źródeł
Nowoczesne przełączniki wykorzystują różne strategie buforowania:
- Bufory dedykowane per-port: Scenariusze opisane powyżej mają bezpośrednie zastosowanie
- Bufory współdzielone: Mikropakiety mogą być lepiej absorbowane, choć długotrwałe nierównowagi nadal prowadzą do drop
- Virtual Output Queuing (VoQ): Umożliwia ochronę krytycznego ruchu przy jednoczesnym odrzucaniu ruchu typu best-effort
Strategie mitygacji
Implementacja QoS
Prawidłowa konfiguracja QoS pozwala na:
- Priorytetyzację krytycznego ruchu
- Kontrolowane odrzucanie mniej ważnych pakietów
- Optymalne wykorzystanie dostępnych buforów
Monitoring i analiza
Regularne monitorowanie wskaźników:
- Output drops per interface
- Buffer utilization
- Queue depth statistics
- Mikropakiety (microbursts)
Planowanie pojemności
Uwzględnienie nie tylko średniego wykorzystania łącza, ale także:
- Wzorców ruchu w czasie rzeczywistym
- Charakterystyki aplikacji generujących ruch
- Tolerancji na opóźnienia różnych typów ruchu
Vibe Engineering
Jeśli myślisz, że AI w sieciach to tylko szybkie generowanie konfiguracji bez zastanowienia, to czas poznać lepsze podejście.
Termin "vibe coding" już się ugruntował w branży IT jako określenie szybkiego, luźnego i nieodpowiedzialnego sposobu tworzenia kodu z pomocą AI - całkowicie opartego na promptach, bez zwracania uwagi na to, jak faktycznie działa rezultat. To zostawia nam lukę terminologiczną: jak powinniśmy nazwać drugi koniec spektrum, gdzie przyspieszamy swoją pracę z LLM-ami, pozostając jednocześnie dumnie i pewnie odpowiedzialni za rozwiązania, które tworzą?
Simon proponuję nazwać to "vibe engineering".
Jedna z mniej wypowiadanych prawd o produktywnej pracy z LLM-ami jest: to jest trudne. Jest wiele głębi w zrozumieniu, jak używać tych narzędzi efektywnie, jest mnóstwo pułapek do uniknięcia, a tempo, w jakim mogą one generować działające rozwiązania, podnosi poprzeczkę dla tego, co człowiek powinien wnosić do procesu.
Rozwój agentów kodujących - narzędzi takich jak Claude Code, OpenAI Codex CLI czy Gemini CLI, które mogą iterować nad kodem, aktywnie testując i modyfikując go, aż osiągną określony cel - dramatycznie zwiększył użyteczność LLM-ów dla rzeczywistych problemów inżynierskich.
LLM-y aktywnie nagradzają istniejące najlepsze praktyki. Jeśli już działasz na wysokim poziomie, AI tylko wzmacnia twoją efektywność:
Automatyczne testowanie
Jeśli twój projekt ma solidny, kompleksowy i stabilny zestaw testów, narzędzia agentycznego kodowania mogą z nim latać. W kontekście sieciowym: jeśli masz pytest do testowania swoich skryptów automatyzacji, nornir do weryfikacji konfiguracji, czy automated testing dla swojej infrastruktury-jako-kod - agent AI może działać pewnie. Bez testów? Może twierdzić, że coś działa, nie testując tego w ogóle.
Planowanie z wyprzedzeniem
Zabranie się za hakowanie czegoś razem idzie znacznie lepiej, jeśli zaczniesz od planu wysokiego poziomu. To zawsze było prawdą dla złożonych wdrożeń sieciowych - design network topology, capacity planning, security policies. Z agentem staje się to jeszcze ważniejsze. Możesz iterować nad planem najpierw, potem przekazać go agentowi do implementacji.
Kompleksowa dokumentacja
Tak jak ludzcy inżynierowie, LLM może utrzymać w swoim kontekście tylko podzbiór bazy kodu (lub infrastruktury) na raz. Możliwość dostarczenia mu odpowiedniej dokumentacji pozwala używać API z innych obszarów bez czytania kodu najpierw. W świecie sieci: dokumentuj swoje standardy, naming conventions, IP addressing schemes, routing policies. Dobra dokumentacja pozwala modelowi budować dopasowaną implementację.
Dobre nawyki kontroli wersji
Możliwość cofnięcia błędów i zrozumienia, kiedy i jak coś zostało zmienione, jest jeszcze ważniejsza, gdy agent kodujący mógł wprowadzić zmiany. To dotyczy nie tylko kodu, ale też konfiguracji sieciowych - Git dla network configs, Terraform state, Ansible playbooks. LLM-y są zadziwiająco kompetentne w Git - mogą same nawigować po historii, żeby wyśledzić pochodzenie bugów.
Efektywna automatyzacja
CI/CD, automated formatting i linting, continuous deployment do środowiska preview - wszystko to, z czego mogą korzystać również narzędzia agentycznego kodowania. W network engineering: automated configuration validation, pre-deployment checks, automated rollback mechanisms.
Kultura code review
To wyjaśnia się samo. Jeśli jesteś szybki i produktywny w code review, będziesz miał znacznie lepszy czas pracy z LLM-ami. To samo dotyczy review zmian konfiguracyjnych czy network change requests.
Bardzo dziwna forma zarządzania
Uzyskanie dobrych rezultatów od agenta kodującego przypomina niepokojąco uzyskanie dobrych rezultatów od ludzkiego współpracownika. Musisz dostarczyć jasne instrukcje, upewnić się, że mają niezbędny kontekst i dostarczyć actionable feedback. Jest łatwiej niż z prawdziwymi ludźmi, bo nie musisz się martwić o ich obrazę - ale wszelkie dotychczasowe doświadczenie w zarządzaniu okaże się zaskakująco użyteczne.
Naprawdę dobry manual QA
Poza automatycznymi testami potrzebujesz być naprawdę dobry w ręcznym testowaniu rozwiązań, włączając przewidywanie i kopanie w edge-cases. W sieciach: umiejętność manual testing connectivity, throughput, failover scenarios.
Silne umiejętności badawcze
Istnieją dziesiątki sposobów rozwiązania dowolnego problemu. Wymyślenie najlepszych opcji i udowodnienie, że podejście działa, zawsze było ważne i pozostaje blokerem przed uwolnieniem agenta do napisania faktycznego kodu czy wygenerowania konfiguracji.
Możliwość wdrożenia do środowiska preview
Jeśli agent zbuduje feature (lub wygeneruje konfigurację), posiadanie sposobu na bezpieczne podejrzenie tego (bez wdrażania prosto do produkcji) sprawia, że review są znacznie bardziej produktywne i znacznie redukuje ryzyko wdrożenia czegoś zepsutego. W network engineering: staging environments, lab testing, configuration validation tools.
Analiza szablonów Jinja2
Jinja2-Linter to narzędzie do statycznej analizy szablonów Jinja2 stworzone z myślą o zgodności z wytycznymi AVD. Pozwala wykrywać błędy składni i problemy ze stylem, uruchamia się w CI, działa jako rozszerzenie dla edytorów (np. VSCode, potencjalnie PyCharm) i można go rozszerzać o własne reguły.
PACP protokołów sieciowych

Strona oferuje darmowy plik ZIP z zapisami przechwyceń ruchu sieciowego (Wireshark) obejmującymi większość popularnych protokołów sieciowych. Materiały mają pomóc w zrozumieniu pakietów i przepływów ruchu. W zestawie znajdują się m.in.: ICMP, IGMP, BGP, OSPF, Spanning Tree, 802.1q (trunking), VXLAN, Identity Service Engine, PIM, QoS, SSL, TCP, Traceroute, HSRP, GRE, ARP, 802.1x, IPv6 (w tym Neighbor Discovery i OSPF dla IPv6) oraz BGP dla rodziny adresów IPv6.
Eliminacja przestojów w zasilaniu PoE
Przeczytaj całą historię
Zarejestruj się teraz, aby przeczytać całą historię i uzyskać dostęp do wszystkich postów za tylko dla płacących subskrybentów.
Subskrybuj